
Menu
Services
Blog
- Software
- Blockchain
- Web3 product
- Smart Contracts
- Mobile app
- Web platform
- AWS Cloud
- NFT marketplace
- DeFi
- Fintech
- AI product
- dApp
- Crypto wallet
Rumble Fish helps entrepreneurs build and launch bespoke digital products.
We take care of the technology, so you can focus on your business
Join the ecosystem
of our satisfied customers:







of our satisfied customers:
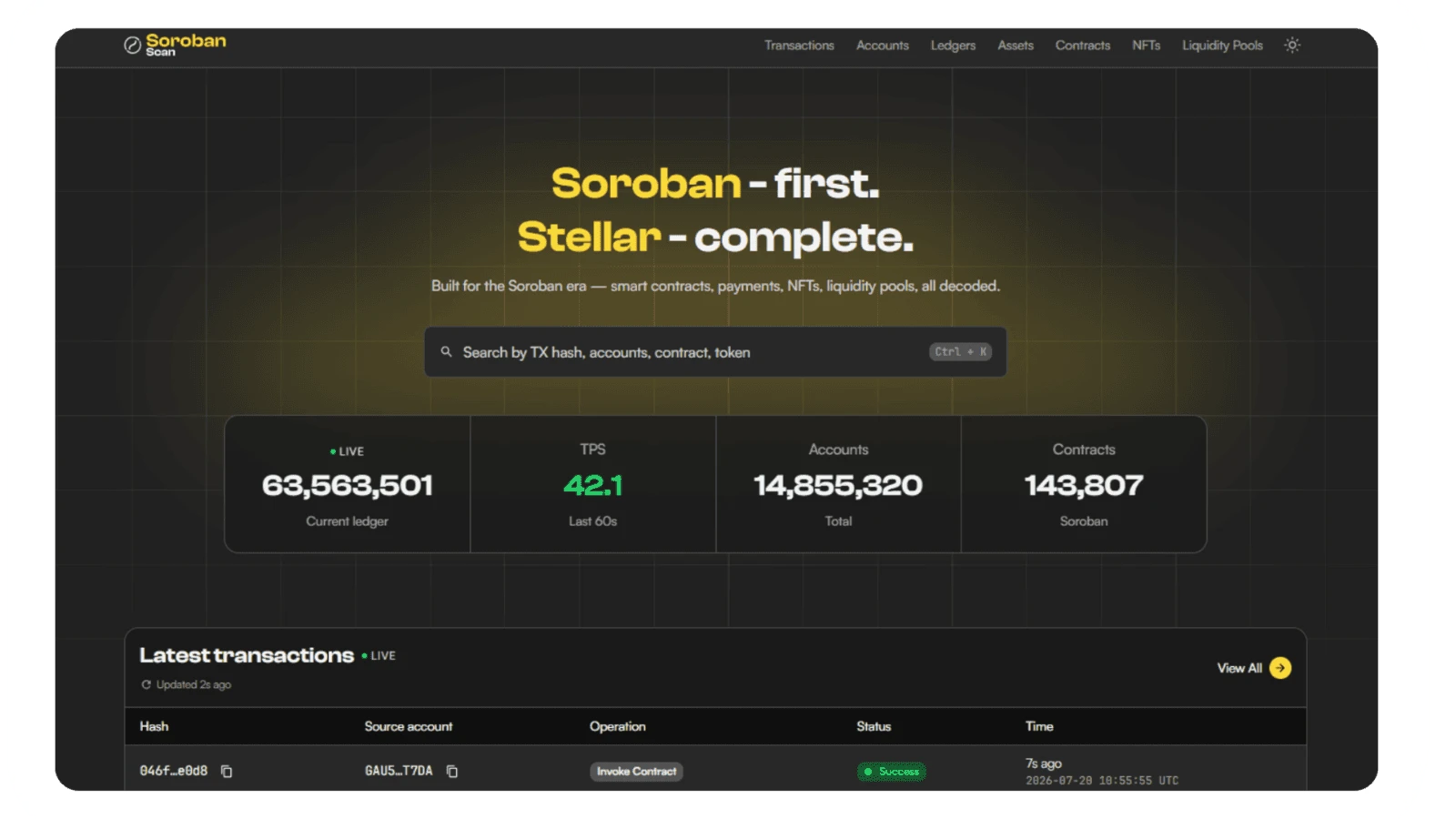
Built with Stellar Community FundSoroban Scan is live on mainnet!Built for the Soroban era - smart contracts, payments, NFTs, liquidity pools, all decoded.Try it now!
Who we are
Hi there! We're Rumble Fish - a team of world-class experts in bespoke software development. Our engineers are highly skilled in blockchain, cloud solutions, and defi/fintech development. Our strength and pride is the ability to take ownership of the entire development process and be a true partner and advisor for our customers. Our mission is to craft state-of-the-art digital products using battle-tested technologies. Try us!




Meet the team
The engineers, strategists, and problem-solvers behind every Rumble Fish project.
40uniquely skilled devs
1pet-friendly office
9years in business
57projects
999passion for coding
What do we do?
Software Development Services and Skills for your needs
Our team is well-versed and experienced in various blockchain development tools and technologies. Our unique skillset allows us to be at the forefront of Web3 development services so if you’re looking for a trusted IT partner to boost your decentralized product - look no further!
We deliver production-ready zero-knowledge proof solutions that actually ship to mainnet, specializing in custom ZK development, rollup scaling solutions, and privacy-preserving smart contracts that reduce processing times from hours to minutes. Try us!
We build fast, compliant, and cost-effective blockchain solutions on the XRP Ledger. From payment systems and tokenization platforms to enterprise DeFi applications, our team delivers production-ready systems that work when billions are on the line.
Rumble Fish builds Stellar and Soroban software for startups, enterprises, and institutions. We develop payment rails, tokenization platforms, smart contracts, and DeFi applications that draw on Stellar's speed, low costs, and financial infrastructure.
We build smart contracts that handle real business complexity without the usual blockchain headaches. From DeFi protocols to custom on-chain systems, we deliver production-ready solutions that scale.
Decentralized Finance (DeFi) development requires an extensive amount of blockchain knowledge, as well as a great understanding of financial mechanisms. We’ve got both that bases covered! Our team has successfully built an impressive number of DeFi products like cryptocurrency exchanges, dApps, lending protocols, or staking platforms. Try us!
Our experienced team will take your AWS cloud solutions to the next level. AWS provides purpose-built tools to support your needs, and it is the preferred choice for any blockchain project. From the plethora of cloud tools and solutions offered by Amazon Web Services, we’ll help you choose and implement the ones that serve your business the best way possible.
AI chatbots can bring value to a wide range of industries by enhancing customer interactions, streamlining processes, and improving overall efficiency. We'll craft a perfect AI assistant for your product.
Need realistic data for AI training, testing, or product development—but privacy, scale, or availability is blocking you? We engineer custom synthetic data solutions that capture the complexity of real-world data without the constraints. From multi-modal generation to domain-specific datasets, we build what platforms can't deliver.
We build custom AI knowledge management systems that turn your scattered enterprise knowledge into instant, accurate answers - no more employees wasting their valuable time hunting through SharePoint and Slack for information. Unlike platforms that trap you in subscriptions, we engineer RAG solutions specifically for your data and security requirements, then hand you complete ownership of the source code and infrastructure.
Looking for a skilled team to help you build an advanced fintech platform able to compete with the biggest in the game? At Rumble Fish, we’ve got what it takes to engineer innovative financial technology systems. We offer end-to-end fintech software development, consulting, and expertise.
Our experts provide you with knowledge, skills, and experience that elevates every project to another level. We’ll gladly take ownership of the entire process and guide you and your team through the intricacies of cutting-edge technology development.
If you’re in need of professional web development services, look no further! Rumble Fish's talented team has extensive experience in delivering top-tier web apps and websites with the use of battle-tested tools and technologies like React or Nest. We know just the right solutions to exceed your business requirements.
Whether you need an Android, an IOS app, or both, the Rumble Fish team is here to help you deliver the beautiful and efficient mobile product that your customers will simply love to use! We craft fast and secure mobile apps with a wow factor to help our customers grow their businesses and reach their goals quicker.
If you're looking for a team capable of turning your product concept into a beautiful and technologically intricate digital solution - look no further! Rumble Fish is your trusted software development partner ready to take you through the entire process of custom digital product creation - from the early stages of ideation to the post-launch support. Whether you're on a mission to build a mobile app, a Web3 product, or an advanced platform - we are here for you!
We design sleek, intuitive, and highly effective interfaces to help you overcome your business challenges. After carefully evaluating and understanding your requirements we switch to the designing mode - the end goal is the beautiful digital solution that people love to use!
Testimonials
See what our customers say about working with us“
Latest case studyPorting Merkl to Stellar: Full Protocol Migration to Soroban
Porting Merkl to Stellar: Full Protocol Migration to Soroban
Collaboration timeframe:4 weeks
Services:Smart Contract Development, Blockchain Development, Stellar Product Development, DeFi Development
We're trusted by global innovators and leaders.Join them!
TURNTABLE
A hybrid of a social network and a music appTURNTABLE
MAKERDAO
The first truly decentralized stablecoin crypto on EthereumMAKERDAO
ZBAY
A private inbox, wallet, and marketplace all in oneZBAY
VERIFYID
An identity verification MVPVERIFYID
Rumblefish Blog ZKP Development Companies in 2026: Who's Actually BuildingBy mid-2026, the ZKP industry had over $3 billion in total funding deployed; zkSync Era and Starknet are serving real transaction volume, Aztec launched on mainnet, and the proving layer, once a bottleneck that made production ZK feel impractical, has crossed into viable territory thanks to specialized prover infrastructure.
This list is not a directory of everyone experimenting with ZK. It focuses on companies that have shipped: production deployments, mainnet systems, or development services with verifiable client work. There are dozens of stealth projects claiming breakthroughs in proof efficiency. Most of them don't belong here yet.
What's changed in the last 18 months is the cost and speed of proof generation. In 2024, generating an Ethereum block proof required a $300–400K GPU cluster and hours of compute time. Today, Succinct's SP1 Hypercube brings that down to around 10 seconds on 16x RTX 5090s. RISC Zero's R0VM 2.0 went from 35 minutes to 44 seconds per block. Those are the numbers that unlock the next category of applications, and the companies below are the ones building on top of that shift.
## Infrastructure: The Proving Layer
The least visible part of the ZK ecosystem is the one that makes everything else possible.
[**Succinct Labs**](https://www.succinct.xyz/) built SP1, a general-purpose zkVM running over RISC-V. Around 90% of the rollup proving market runs on SP1, including Optimism, Base, and Unichain. Their Prover Network, backed by a $PROVE token and launched in 2025 after a $55M Series A led by Paradigm, decentralizes proof generation so projects don't need to own GPU infrastructure. SP1 Hypercube is the current performance frontier: roughly 10 seconds per Ethereum block proof at around $0.02 per proof, on hardware that costs $24–48K to own rather than $300–400K.
[**RISC Zero**](https://risczero.com/) takes a similar zkVM approach (write Rust programs, get ZK proofs of execution) and has a different economic model. Their Boundless marketplace, live on mainnet since September 2025, has processed 542 trillion cycles and 399K orders. R0VM 2.0 dropped block proving time from 35 minutes to 44 seconds. They claim 7x lower cost than SP1, though benchmark comparisons between proving systems are notoriously dependent on workload type.
[**Irreducible**](https://www.irreducible.com/) is the one to watch for the medium term. They're building Binius, a proof system that operates over binary fields instead of the large prime fields used by most SNARKs and STARKs. The practical implication is that binary computation, which is how CPUs actually work, can be proven much more directly, targeting 10–100x efficiency improvement over prime-field proofs. Vitalik Buterin wrote a detailed explainer on it. Polygon Labs is partnering on a Binius-based zkVM. $39M raised from Paradigm and Bain Capital Crypto, and still in research-to-production development.

[**Ingonyama**](https://www.ingonyama.com/) is doing hardware acceleration via ICICLE, an open-source GPU acceleration library for ZK provers. If you have a proof system and want it to run faster on GPUs without rewriting your cryptography, ICICLE is the library. They're also building FPGA and custom silicon implementations. The $21M seed from IOSG, Walden Catalyst, and Samsung Next reflects a bet that proving costs will continue to drop as specialized hardware catches up.
## Rollups: The L2 Battlefield
The major zkEVM rollups are past the "will this work" phase and into the "how fast, how cheap, and for whom" phase.
[**Matter Labs**](https://matterlabs.com/) is probably the most ambitious bet in the space right now. $458M raised, and the 2026 roadmap points clearly at institutional finance. Prividium, their private permissioned blockchain for regulated financial institutions, has five U.S. banks representing over $600B in deposits building on it through Cari Network. The Elastic Chain vision (multiple application-specific ZK chains sharing a common proving layer, interoperating natively) is becoming real: ZIP-16 introduced native cross-chain token transfers between ZKsync chains in May 2026, with fees denominated in $ZK. This is no longer just a scaling play; it's infrastructure for compliant institutional DeFi.
[**StarkWare**](https://starkware.co/) invented STARK proofs and remains the only major L2 team that is also the research origin of its proof system. Starknet is the production rollup; StarkEx is the permissioned scaling engine behind dYdX, Immutable X, and Sorare. The $8B valuation from the Series D in 2022 looked aggressive at the time. What's notable is the post-quantum angle: STARKs are hash-based and carry no elliptic curve dependency, which makes them resistant to future quantum attacks in a way that SNARK-based systems are not. That argument has gotten louder as quantum computing timelines have shortened.
[**Aztec Network**](https://aztec.network/) is the one doing something the others are deliberately not doing: privacy by default. Most ZK rollups use zero-knowledge proofs for scaling: the validity proof proves the computation was correct, but the transactions themselves remain visible on Ethereum. Aztec's architecture separates private execution (done locally on the user's device via PXE) from public settlement (submitted to Ethereum). Contracts can define exactly which data is public and which stays private, and those privacy rules compose across contract calls. Mainnet launched in November 2025. The token generation event happened in February 2026. Full private smart contract execution is rolling out through 2026. Backed by a16z and Paradigm with over $180M combined equity and token rounds.

[**Polygon**](https://polygon.technology/) is the largest ZK ecosystem by capital deployed, $451M in funding plus a $1B+ ZK treasury, and also the most fragmented. Polygon zkEVM is the main production rollup (sub-2.5 second confirmation, $0.015 average fee). Polygon Miden is a STARK-based VM with a distinct design philosophy. Polygon Zero uses recursive proofs. The acquisition of Toposware in 2024 and the $5M purchase of Fabric VPU hardware signals continued infrastructure investment. The risk with Polygon's ZK story is the breadth: three separate ZK product lines with different proof systems require a lot of engineering coordination to maintain and differentiate.
## Privacy Blockchain Development: Applications Layer
[**Zcash**](https://z.cash/) matters because it has ten years of production ZK-SNARK deployment, which no one else can claim. The Halo 2 upgrade removed the trusted setup requirement that had been a persistent criticism of the original Groth16 proofs. The shielded pool crossed 4.5M ZEC in late 2025. Market cap surged past $6.3B. For teams evaluating privacy blockchain development in financial contexts, Zcash is the only project with a decade-long track record of ZK proofs in production under adversarial conditions.
[**Worldcoin / World**](https://world.org/) is the largest real-world ZK deployment by user count: over 10 million people verified as unique humans via iris scan, with ZK proofs ensuring the biometric data never leaves the Orb. Whether or not you have opinions about the project's approach to identity, the engineering is real and deployed at a scale no other ZK application has reached.
## ZK Proof Services: Development Partners
Most of the companies above are building protocols, infrastructure, or applications on their own roadmap. If you're a company that wants to integrate ZK into your product (a private voting system, a confidential DeFi protocol, a compliance tool that proves regulatory requirements without exposing user data), you need a different kind of partner.
[**Rumble Fish**](https://www.rumblefish.dev/services/zero-knowledge-proof-development/) sits in this category. The Kraków-based team works across the full ZK development stack: custom circuit design using Circom, Noir, gnark, and arkworks; rollup implementations; privacy-preserving smart contracts; and integration into production systems. The work is concrete: they built a decentralized registry using zero-knowledge cryptography for Original Works, reducing ZK proof processing time significantly using RISC Zero and Rust. The ZKP service covers zk-SNARKs for shielded transactions, zk-STARKs for scalable proofs, and PLONK-based systems, which is a broader proof system coverage than most development shops maintain.
What distinguishes a ZK development partner from a ZK protocol company is scope. Protocol companies own their infrastructure and build on their own timeline. A development partner works within yours, translating a product requirement into a proof system architecture and delivering a working implementation. For teams that don't want to hire a cryptography department, this is the practical path to shipping ZKP functionality.
## How to Read This Landscape in 2026
The question of which ZKP development company to work with depends on what you're actually trying to build. If you need a production ZK rollup for Ethereum scaling, the zkEVM options (zkSync Era, Scroll, Polygon zkEVM) are mature enough to evaluate seriously on their developer experience, ecosystem, and fee structure rather than proof system stability.
If privacy is the primary requirement, not just as a side effect but as the core feature, Aztec is the only production system designed around it from the start. The privacy vs. regulatory compliance tension is real and unresolved at the protocol level, but the cryptography works.
If you're building something that generates ZK proofs as part of a larger application (not a rollup, but a compliance tool, a voting system, a confidential data product) the proving infrastructure from Succinct or RISC Zero makes self-hosted proof generation cheaper than it has ever been. Whether you build on top of that infrastructure yourself or engage a ZK development partner depends on how much cryptographic expertise you can justify building in-house.
The consolidation that has happened in the last 18 months is real. The theoretical layer is largely settled. What's left is engineering, adoption, and the slow process of proving that ZK proofs can carry the compliance and privacy requirements of regulated industries: not just in test environments, but in production, under audit, with real money moving through them.
ZKP Development Companies in 2026: Who's Actually BuildingBy mid-2026, the ZKP industry had over $3 billion in total funding deployed; zkSync Era and Starknet are serving real transaction volume, Aztec launched on mainnet, and the proving layer, once a bottleneck that made production ZK feel impractical, has crossed into viable territory thanks to specialized prover infrastructure.
This list is not a directory of everyone experimenting with ZK. It focuses on companies that have shipped: production deployments, mainnet systems, or development services with verifiable client work. There are dozens of stealth projects claiming breakthroughs in proof efficiency. Most of them don't belong here yet.
What's changed in the last 18 months is the cost and speed of proof generation. In 2024, generating an Ethereum block proof required a $300–400K GPU cluster and hours of compute time. Today, Succinct's SP1 Hypercube brings that down to around 10 seconds on 16x RTX 5090s. RISC Zero's R0VM 2.0 went from 35 minutes to 44 seconds per block. Those are the numbers that unlock the next category of applications, and the companies below are the ones building on top of that shift.
## Infrastructure: The Proving Layer
The least visible part of the ZK ecosystem is the one that makes everything else possible.
[**Succinct Labs**](https://www.succinct.xyz/) built SP1, a general-purpose zkVM running over RISC-V. Around 90% of the rollup proving market runs on SP1, including Optimism, Base, and Unichain. Their Prover Network, backed by a $PROVE token and launched in 2025 after a $55M Series A led by Paradigm, decentralizes proof generation so projects don't need to own GPU infrastructure. SP1 Hypercube is the current performance frontier: roughly 10 seconds per Ethereum block proof at around $0.02 per proof, on hardware that costs $24–48K to own rather than $300–400K.

[**RISC Zero**](https://risczero.com/) takes a similar zkVM approach (write Rust programs, get ZK proofs of execution) and has a different economic model. Their Boundless marketplace, live on mainnet since September 2025, has processed 542 trillion cycles and 399K orders. R0VM 2.0 dropped block proving time from 35 minutes to 44 seconds. They claim 7x lower cost than SP1, though benchmark comparisons between proving systems are notoriously dependent on workload type.
[**Irreducible**](https://www.irreducible.com/) is the one to watch for the medium term. They're building Binius, a proof system that operates over binary fields instead of the large prime fields used by most SNARKs and STARKs. The practical implication is that binary computation, which is how CPUs actually work, can be proven much more directly, targeting 10–100x efficiency improvement over prime-field proofs. Vitalik Buterin wrote a detailed explainer on it. Polygon Labs is partnering on a Binius-based zkVM. $39M raised from Paradigm and Bain Capital Crypto, and still in research-to-production development.

[**Ingonyama**](https://www.ingonyama.com/) is doing hardware acceleration via ICICLE, an open-source GPU acceleration library for ZK provers. If you have a proof system and want it to run faster on GPUs without rewriting your cryptography, ICICLE is the library. They're also building FPGA and custom silicon implementations. The $21M seed from IOSG, Walden Catalyst, and Samsung Next reflects a bet that proving costs will continue to drop as specialized hardware catches up.
## Rollups: The L2 Battlefield
The major zkEVM rollups are past the "will this work" phase and into the "how fast, how cheap, and for whom" phase.
[**Matter Labs**](https://matterlabs.com/) is probably the most ambitious bet in the space right now. $458M raised, and the 2026 roadmap points clearly at institutional finance. Prividium, their private permissioned blockchain for regulated financial institutions, has five U.S. banks representing over $600B in deposits building on it through Cari Network. The Elastic Chain vision (multiple application-specific ZK chains sharing a common proving layer, interoperating natively) is becoming real: ZIP-16 introduced native cross-chain token transfers between ZKsync chains in May 2026, with fees denominated in $ZK. This is no longer just a scaling play; it's infrastructure for compliant institutional DeFi.
[**StarkWare**](https://starkware.co/) invented STARK proofs and remains the only major L2 team that is also the research origin of its proof system. Starknet is the production rollup; StarkEx is the permissioned scaling engine behind dYdX, Immutable X, and Sorare. The $8B valuation from the Series D in 2022 looked aggressive at the time. What's notable is the post-quantum angle: STARKs are hash-based and carry no elliptic curve dependency, which makes them resistant to future quantum attacks in a way that SNARK-based systems are not. That argument has gotten louder as quantum computing timelines have shortened.
[**Aztec Network**](https://aztec.network/) is the one doing something the others are deliberately not doing: privacy by default. Most ZK rollups use zero-knowledge proofs for scaling: the validity proof proves the computation was correct, but the transactions themselves remain visible on Ethereum. Aztec's architecture separates private execution (done locally on the user's device via PXE) from public settlement (submitted to Ethereum). Contracts can define exactly which data is public and which stays private, and those privacy rules compose across contract calls. Mainnet launched in November 2025. The token generation event happened in February 2026. Full private smart contract execution is rolling out through 2026. Backed by a16z and Paradigm with over $180M combined equity and token rounds.

[**Polygon**](https://polygon.technology/) is the largest ZK ecosystem by capital deployed, $451M in funding plus a $1B+ ZK treasury, and also the most fragmented. Polygon zkEVM is the main production rollup (sub-2.5 second confirmation, $0.015 average fee). Polygon Miden is a STARK-based VM with a distinct design philosophy. Polygon Zero uses recursive proofs. The acquisition of Toposware in 2024 and the $5M purchase of Fabric VPU hardware signals continued infrastructure investment. The risk with Polygon's ZK story is the breadth: three separate ZK product lines with different proof systems require a lot of engineering coordination to maintain and differentiate.
## Privacy Blockchain Development: Applications Layer
[**Zcash**](https://z.cash/) matters because it has ten years of production ZK-SNARK deployment, which no one else can claim. The Halo 2 upgrade removed the trusted setup requirement that had been a persistent criticism of the original Groth16 proofs. The shielded pool crossed 4.5M ZEC in late 2025. Market cap surged past $6.3B. For teams evaluating privacy blockchain development in financial contexts, Zcash is the only project with a decade-long track record of ZK proofs in production under adversarial conditions.
[**Worldcoin / World**](https://world.org/) is the largest real-world ZK deployment by user count: over 10 million people verified as unique humans via iris scan, with ZK proofs ensuring the biometric data never leaves the Orb. Whether or not you have opinions about the project's approach to identity, the engineering is real and deployed at a scale no other ZK application has reached.
## ZK Proof Services: Development Partners
Most of the companies above are building protocols, infrastructure, or applications on their own roadmap. If you're a company that wants to integrate ZK into your product (a private voting system, a confidential DeFi protocol, a compliance tool that proves regulatory requirements without exposing user data), you need a different kind of partner.
[**Rumble Fish**](https://www.rumblefish.dev/services/zero-knowledge-proof-development/) sits in this category. The Kraków-based team works across the full ZK development stack: custom circuit design using Circom, Noir, gnark, and arkworks; rollup implementations; privacy-preserving smart contracts; and integration into production systems. The work is concrete: they built a decentralized registry using zero-knowledge cryptography for Original Works, reducing ZK proof processing time significantly using RISC Zero and Rust. The ZKP service covers zk-SNARKs for shielded transactions, zk-STARKs for scalable proofs, and PLONK-based systems, which is a broader proof system coverage than most development shops maintain.
What distinguishes a ZK development partner from a ZK protocol company is scope. Protocol companies own their infrastructure and build on their own timeline. A development partner works within yours, translating a product requirement into a proof system architecture and delivering a working implementation. For teams that don't want to hire a cryptography department, this is the practical path to shipping ZKP functionality.
## How to Read This Landscape in 2026
The question of which ZKP development company to work with depends on what you're actually trying to build. If you need a production ZK rollup for Ethereum scaling, the zkEVM options (zkSync Era, Scroll, Polygon zkEVM) are mature enough to evaluate seriously on their developer experience, ecosystem, and fee structure rather than proof system stability.
If privacy is the primary requirement, not just as a side effect but as the core feature, Aztec is the only production system designed around it from the start. The privacy vs. regulatory compliance tension is real and unresolved at the protocol level, but the cryptography works.
If you're building something that generates ZK proofs as part of a larger application (not a rollup, but a compliance tool, a voting system, a confidential data product) the proving infrastructure from Succinct or RISC Zero makes self-hosted proof generation cheaper than it has ever been. Whether you build on top of that infrastructure yourself or engage a ZK development partner depends on how much cryptographic expertise you can justify building in-house.
The consolidation that has happened in the last 18 months is real. The theoretical layer is largely settled. What's left is engineering, adoption, and the slow process of proving that ZK proofs can carry the compliance and privacy requirements of regulated industries: not just in test environments, but in production, under audit, with real money moving through them. Soroban Scan Is Live: The Soroban Block Explorer Built for the Whole Ecosystem
Soroban Scan Is Live: The Soroban Block Explorer Built for the Whole Ecosystem By Agnieszka DoboszEarlier this year, Rumble Fish received a $131,200 grant from the Stellar Community Fund to build a Soroban-first block explorer. Today, that tool is publicly available at [sorobanscan.rumblefish.dev](https://sorobanscan.rumblefish.dev).
The grant announcement covered what we were going to build and why. This one covers what we actually shipped, what we learned building it, and what we want from the community now that it's live.
## What Soroban Scan Does
If you've tried to debug Soroban transactions using existing tools, you know the problem. Events show up as raw XDR. Contract invocations are unreadable without manually decoding binary data. Account history is incomplete or absent for anything Soroban-specific. For anyone who isn't fluent in the Stellar protocol's binary formats, existing explorers offer very little. Soroban Scan is built around the assumption that block explorers should be readable by developers, users, and anyone curious about what's happening on-chain, not just protocol engineers who know how to interpret XDR.
Transaction pages show Soroban invocations with decoded function names, arguments, and return values. If a transaction called a swap function with specific token amounts, you see the function name and the amounts, not a hex string. Contract pages list all invocations of a given contract with the same human-readable decoding applied across the board. Function signatures are extracted from the WASM bytecode at deployment time, which is what makes decoding possible without a separate ABI file.
Event tabs decode CAP-67 contract events into structured tables: topics and data fields presented as typed values, not opaque base64 blobs. For DeFi activity like swaps, transfers, and liquidity changes, the Event Interpreter layer generates plain-language summaries. Account pages surface Soroban-specific history: which contracts an account has interacted with, what those interactions did, and the full event trail. Global search covers transaction hashes, account IDs, and contract IDs.
## How We Got Here
The build followed the three-tranche structure in our SCF submission. Tranche 1 was the data pipeline: Galexie running on ECS Fargate, writing LedgerCloseMeta XDR files to S3 every five to six seconds, a Rust Lambda firing on each file to parse and write to our database, and the CloudWatch monitoring stack. By the end of Tranche 1, we were ingesting live mainnet data reliably.
Tranche 2 brought the frontend and the full API surface: all REST endpoints, the React SPA with transaction, ledger, account, contract, and search pages, and the Event Interpreter that generates human-readable summaries for known DeFi protocol interactions. The staging environment at this point was showing live mainnet data with Soroban events decoded.
Tranche 3 was production hardening: load testing to p95 under 200ms at 1 million requests/month equivalent load, a security audit against OWASP Top 10, full API documentation, CI/CD via GitHub Actions, and a seven-day post-launch monitoring report. The architecture is AWS-first (Lambda, ECS Fargate, API Gateway, CloudFront), with a ClickHouse database on Hetzner that turned a projected 7 TB PostgreSQL dataset into roughly 900 MB.
One thing that was genuinely harder than the architecture docs suggested: the historical backfill. Soroban has been on mainnet since late 2023, which meant indexing roughly two years of history before going live. We ended up running the backfill on local machines writing to a local ClickHouse instance, then migrating the result to production, because the event-driven pipeline optimised for continuous ingestion is simply the wrong shape for a one-time bulk operation across millions of ledgers.
## What We Need From You
Soroban Scan is live and stable, but no block explorer gets to call itself finished at launch. The DeFi protocol coverage in the Event Interpreter is real but limited. We're pattern-matching against Soroswap, Aquarius, and Phoenix today, and every Soroban project that builds something new is a new case to handle. Contract decoding works for contracts that embed their WASM, but the ecosystem is growing, and there will be edge cases we haven't seen.
To use Soroban Scan as a Soroban debugger: paste any transaction hash from a smart contract invocation into the search and open the detail page. The decoded function arguments, return values, and event trail are on one page. If something looks wrong, or if a transaction you'd expect to be readable isn't, that's exactly the kind of feedback we need.
Useful things to tell us: contracts or protocols where events aren't decoding correctly; transactions where the human-readable summary is wrong or missing; search edge cases where a transaction hash, account ID, or contract ID returns something unexpected; anything about the UI that makes it harder to understand what a transaction actually did.
[GitHub issues are open.](https://github.com/rumblefishdev/soroban-block-explorer/issues/new) We're also in the Stellar Discord and Telegram. If you're building on Soroban and want your contracts well-represented in the explorer, reach out directly.
The tool is free and indexed from Soroban genesis.
Try it out here → [sorobanscan.rumblefish.dev](https://sorobanscan.rumblefish.dev).
By Agnieszka DoboszEarlier this year, Rumble Fish received a $131,200 grant from the Stellar Community Fund to build a Soroban-first block explorer. Today, that tool is publicly available at [sorobanscan.rumblefish.dev](https://sorobanscan.rumblefish.dev).
The grant announcement covered what we were going to build and why. This one covers what we actually shipped, what we learned building it, and what we want from the community now that it's live.
## What Soroban Scan Does
If you've tried to debug Soroban transactions using existing tools, you know the problem. Events show up as raw XDR. Contract invocations are unreadable without manually decoding binary data. Account history is incomplete or absent for anything Soroban-specific. For anyone who isn't fluent in the Stellar protocol's binary formats, existing explorers offer very little. Soroban Scan is built around the assumption that block explorers should be readable by developers, users, and anyone curious about what's happening on-chain, not just protocol engineers who know how to interpret XDR.
Transaction pages show Soroban invocations with decoded function names, arguments, and return values. If a transaction called a swap function with specific token amounts, you see the function name and the amounts, not a hex string. Contract pages list all invocations of a given contract with the same human-readable decoding applied across the board. Function signatures are extracted from the WASM bytecode at deployment time, which is what makes decoding possible without a separate ABI file.
Event tabs decode CAP-67 contract events into structured tables: topics and data fields presented as typed values, not opaque base64 blobs. For DeFi activity like swaps, transfers, and liquidity changes, the Event Interpreter layer generates plain-language summaries. Account pages surface Soroban-specific history: which contracts an account has interacted with, what those interactions did, and the full event trail. Global search covers transaction hashes, account IDs, and contract IDs.
## How We Got Here
The build followed the three-tranche structure in our SCF submission. Tranche 1 was the data pipeline: Galexie running on ECS Fargate, writing LedgerCloseMeta XDR files to S3 every five to six seconds, a Rust Lambda firing on each file to parse and write to our database, and the CloudWatch monitoring stack. By the end of Tranche 1, we were ingesting live mainnet data reliably.
Tranche 2 brought the frontend and the full API surface: all REST endpoints, the React SPA with transaction, ledger, account, contract, and search pages, and the Event Interpreter that generates human-readable summaries for known DeFi protocol interactions. The staging environment at this point was showing live mainnet data with Soroban events decoded.
Tranche 3 was production hardening: load testing to p95 under 200ms at 1 million requests/month equivalent load, a security audit against OWASP Top 10, full API documentation, CI/CD via GitHub Actions, and a seven-day post-launch monitoring report. The architecture is AWS-first (Lambda, ECS Fargate, API Gateway, CloudFront), with a ClickHouse database on Hetzner that turned a projected 7 TB PostgreSQL dataset into roughly 900 MB.
One thing that was genuinely harder than the architecture docs suggested: the historical backfill. Soroban has been on mainnet since late 2023, which meant indexing roughly two years of history before going live. We ended up running the backfill on local machines writing to a local ClickHouse instance, then migrating the result to production, because the event-driven pipeline optimised for continuous ingestion is simply the wrong shape for a one-time bulk operation across millions of ledgers.
## What We Need From You
Soroban Scan is live and stable, but no block explorer gets to call itself finished at launch. The DeFi protocol coverage in the Event Interpreter is real but limited. We're pattern-matching against Soroswap, Aquarius, and Phoenix today, and every Soroban project that builds something new is a new case to handle. Contract decoding works for contracts that embed their WASM, but the ecosystem is growing, and there will be edge cases we haven't seen.
To use Soroban Scan as a Soroban debugger: paste any transaction hash from a smart contract invocation into the search and open the detail page. The decoded function arguments, return values, and event trail are on one page. If something looks wrong, or if a transaction you'd expect to be readable isn't, that's exactly the kind of feedback we need.
Useful things to tell us: contracts or protocols where events aren't decoding correctly; transactions where the human-readable summary is wrong or missing; search edge cases where a transaction hash, account ID, or contract ID returns something unexpected; anything about the UI that makes it harder to understand what a transaction actually did.
[GitHub issues are open.](https://github.com/rumblefishdev/soroban-block-explorer/issues/new) We're also in the Stellar Discord and Telegram. If you're building on Soroban and want your contracts well-represented in the explorer, reach out directly.
The tool is free and indexed from Soroban genesis.
Try it out here → [sorobanscan.rumblefish.dev](https://sorobanscan.rumblefish.dev).
Check a piece of expert knowledge
ZKP Development Companies in 2026: Who's Actually BuildingBy mid-2026, the ZKP industry had over $3 billion in total funding deployed; zkSync Era and Starknet are serving real transaction volume, Aztec launched on mainnet, and the proving layer, once a bottleneck that made production ZK feel impractical, has crossed into viable territory thanks to specialized prover infrastructure.
This list is not a directory of everyone experimenting with ZK. It focuses on companies that have shipped: production deployments, mainnet systems, or development services with verifiable client work. There are dozens of stealth projects claiming breakthroughs in proof efficiency. Most of them don't belong here yet.
What's changed in the last 18 months is the cost and speed of proof generation. In 2024, generating an Ethereum block proof required a $300–400K GPU cluster and hours of compute time. Today, Succinct's SP1 Hypercube brings that down to around 10 seconds on 16x RTX 5090s. RISC Zero's R0VM 2.0 went from 35 minutes to 44 seconds per block. Those are the numbers that unlock the next category of applications, and the companies below are the ones building on top of that shift.
## Infrastructure: The Proving Layer
The least visible part of the ZK ecosystem is the one that makes everything else possible.
[**Succinct Labs**](https://www.succinct.xyz/) built SP1, a general-purpose zkVM running over RISC-V. Around 90% of the rollup proving market runs on SP1, including Optimism, Base, and Unichain. Their Prover Network, backed by a $PROVE token and launched in 2025 after a $55M Series A led by Paradigm, decentralizes proof generation so projects don't need to own GPU infrastructure. SP1 Hypercube is the current performance frontier: roughly 10 seconds per Ethereum block proof at around $0.02 per proof, on hardware that costs $24–48K to own rather than $300–400K.

[**RISC Zero**](https://risczero.com/) takes a similar zkVM approach (write Rust programs, get ZK proofs of execution) and has a different economic model. Their Boundless marketplace, live on mainnet since September 2025, has processed 542 trillion cycles and 399K orders. R0VM 2.0 dropped block proving time from 35 minutes to 44 seconds. They claim 7x lower cost than SP1, though benchmark comparisons between proving systems are notoriously dependent on workload type.
[**Irreducible**](https://www.irreducible.com/) is the one to watch for the medium term. They're building Binius, a proof system that operates over binary fields instead of the large prime fields used by most SNARKs and STARKs. The practical implication is that binary computation, which is how CPUs actually work, can be proven much more directly, targeting 10–100x efficiency improvement over prime-field proofs. Vitalik Buterin wrote a detailed explainer on it. Polygon Labs is partnering on a Binius-based zkVM. $39M raised from Paradigm and Bain Capital Crypto, and still in research-to-production development.

[**Ingonyama**](https://www.ingonyama.com/) is doing hardware acceleration via ICICLE, an open-source GPU acceleration library for ZK provers. If you have a proof system and want it to run faster on GPUs without rewriting your cryptography, ICICLE is the library. They're also building FPGA and custom silicon implementations. The $21M seed from IOSG, Walden Catalyst, and Samsung Next reflects a bet that proving costs will continue to drop as specialized hardware catches up.
## Rollups: The L2 Battlefield
The major zkEVM rollups are past the "will this work" phase and into the "how fast, how cheap, and for whom" phase.
[**Matter Labs**](https://matterlabs.com/) is probably the most ambitious bet in the space right now. $458M raised, and the 2026 roadmap points clearly at institutional finance. Prividium, their private permissioned blockchain for regulated financial institutions, has five U.S. banks representing over $600B in deposits building on it through Cari Network. The Elastic Chain vision (multiple application-specific ZK chains sharing a common proving layer, interoperating natively) is becoming real: ZIP-16 introduced native cross-chain token transfers between ZKsync chains in May 2026, with fees denominated in $ZK. This is no longer just a scaling play; it's infrastructure for compliant institutional DeFi.
[**StarkWare**](https://starkware.co/) invented STARK proofs and remains the only major L2 team that is also the research origin of its proof system. Starknet is the production rollup; StarkEx is the permissioned scaling engine behind dYdX, Immutable X, and Sorare. The $8B valuation from the Series D in 2022 looked aggressive at the time. What's notable is the post-quantum angle: STARKs are hash-based and carry no elliptic curve dependency, which makes them resistant to future quantum attacks in a way that SNARK-based systems are not. That argument has gotten louder as quantum computing timelines have shortened.
[**Aztec Network**](https://aztec.network/) is the one doing something the others are deliberately not doing: privacy by default. Most ZK rollups use zero-knowledge proofs for scaling: the validity proof proves the computation was correct, but the transactions themselves remain visible on Ethereum. Aztec's architecture separates private execution (done locally on the user's device via PXE) from public settlement (submitted to Ethereum). Contracts can define exactly which data is public and which stays private, and those privacy rules compose across contract calls. Mainnet launched in November 2025. The token generation event happened in February 2026. Full private smart contract execution is rolling out through 2026. Backed by a16z and Paradigm with over $180M combined equity and token rounds.

[**Polygon**](https://polygon.technology/) is the largest ZK ecosystem by capital deployed, $451M in funding plus a $1B+ ZK treasury, and also the most fragmented. Polygon zkEVM is the main production rollup (sub-2.5 second confirmation, $0.015 average fee). Polygon Miden is a STARK-based VM with a distinct design philosophy. Polygon Zero uses recursive proofs. The acquisition of Toposware in 2024 and the $5M purchase of Fabric VPU hardware signals continued infrastructure investment. The risk with Polygon's ZK story is the breadth: three separate ZK product lines with different proof systems require a lot of engineering coordination to maintain and differentiate.
## Privacy Blockchain Development: Applications Layer
[**Zcash**](https://z.cash/) matters because it has ten years of production ZK-SNARK deployment, which no one else can claim. The Halo 2 upgrade removed the trusted setup requirement that had been a persistent criticism of the original Groth16 proofs. The shielded pool crossed 4.5M ZEC in late 2025. Market cap surged past $6.3B. For teams evaluating privacy blockchain development in financial contexts, Zcash is the only project with a decade-long track record of ZK proofs in production under adversarial conditions.
[**Worldcoin / World**](https://world.org/) is the largest real-world ZK deployment by user count: over 10 million people verified as unique humans via iris scan, with ZK proofs ensuring the biometric data never leaves the Orb. Whether or not you have opinions about the project's approach to identity, the engineering is real and deployed at a scale no other ZK application has reached.
## ZK Proof Services: Development Partners
Most of the companies above are building protocols, infrastructure, or applications on their own roadmap. If you're a company that wants to integrate ZK into your product (a private voting system, a confidential DeFi protocol, a compliance tool that proves regulatory requirements without exposing user data), you need a different kind of partner.
[**Rumble Fish**](https://www.rumblefish.dev/services/zero-knowledge-proof-development/) sits in this category. The Kraków-based team works across the full ZK development stack: custom circuit design using Circom, Noir, gnark, and arkworks; rollup implementations; privacy-preserving smart contracts; and integration into production systems. The work is concrete: they built a decentralized registry using zero-knowledge cryptography for Original Works, reducing ZK proof processing time significantly using RISC Zero and Rust. The ZKP service covers zk-SNARKs for shielded transactions, zk-STARKs for scalable proofs, and PLONK-based systems, which is a broader proof system coverage than most development shops maintain.
What distinguishes a ZK development partner from a ZK protocol company is scope. Protocol companies own their infrastructure and build on their own timeline. A development partner works within yours, translating a product requirement into a proof system architecture and delivering a working implementation. For teams that don't want to hire a cryptography department, this is the practical path to shipping ZKP functionality.
## How to Read This Landscape in 2026
The question of which ZKP development company to work with depends on what you're actually trying to build. If you need a production ZK rollup for Ethereum scaling, the zkEVM options (zkSync Era, Scroll, Polygon zkEVM) are mature enough to evaluate seriously on their developer experience, ecosystem, and fee structure rather than proof system stability.
If privacy is the primary requirement, not just as a side effect but as the core feature, Aztec is the only production system designed around it from the start. The privacy vs. regulatory compliance tension is real and unresolved at the protocol level, but the cryptography works.
If you're building something that generates ZK proofs as part of a larger application (not a rollup, but a compliance tool, a voting system, a confidential data product) the proving infrastructure from Succinct or RISC Zero makes self-hosted proof generation cheaper than it has ever been. Whether you build on top of that infrastructure yourself or engage a ZK development partner depends on how much cryptographic expertise you can justify building in-house.
The consolidation that has happened in the last 18 months is real. The theoretical layer is largely settled. What's left is engineering, adoption, and the slow process of proving that ZK proofs can carry the compliance and privacy requirements of regulated industries: not just in test environments, but in production, under audit, with real money moving through them.Blockchain
Soroban Scan Is Live: The Soroban Block Explorer Built for the Whole EcosystemBy Agnieszka DoboszBlockchain
Have an idea?
Let’s work
together!We will answer any questions you may have related to your startup journey!Do you prefer e-mail?
hello@rumblefish.pl
together!We will answer any questions you may have related to your startup journey!Do you prefer e-mail?
hello@rumblefish.pl


RUMBLEFISH POLAND SP Z O.O.Filipa Eisenberga 11/3 31-523 Kraków, Polska
NIP: 6772425725REGON: 368368380KRS: 0000696628
P: +48 601 265 364E: hello@rumblefish.dev
Copyright © 2026 RumblefishServicesBlockchain Software DevelopmentZero-Knowledge Proof DevelopmentXRPL Blockchain DevelopmentStellar Product DevelopmentSmart Contract DevelopmentDeFi DevelopmentAWS Cloud SolutionsAI Chat Assistant DevelopmentSynthetic Data GenerationFintech Software DevelopmentDedicated Development TeamsWeb developmentMobile developmentIT Services for startupUI/UXRust Web App DevelopmentView all services
CareersJoin Our Team


